来自 MIT CSAIL 和 IAIFI 的研究者将准确的 3D 几何图形与来自 2D 基础模型的丰富语义结合起来,让机器人能够利用 2D 基础模型中丰富的视觉和语言先验,完成语言指导的操作。
最近,具身智能成为人工智能领域关注的一个焦点。从斯坦福大学的 VIMA 机器人智能体,到谷歌 DeepMind 推出首个控制机器人的视觉 - 语言 - 动作(VLA)的模型 RT-2,大模型加持的机器人研究备受关注。
当前,自监督和语言监督的图像模型已经包含丰富的世界知识,这对于泛化来说非常重要,但图像特征是二维的。我们知道,机器人任务通常需要对现实世界中三维物体的几何形状有所了解。
基于此,来自 MIT CSAIL 和 IAIFI 的研究者利用蒸馏特征场(Distilled Feature Field,DFF),将准确的 3D 几何图形与来自 2D 基础模型的丰富语义结合起来,让机器人能够利用 2D 基础模型中丰富的视觉和语言先验,完成语言指导的操作。

论文地址:https://arxiv.org/abs/2308.07931
具体来说,该研究提出了一种用于 6-DOF 抓取和放置的小样本学习方法,并利用强大的空间和语义先验泛化到未见过物体上。使用从视觉 - 语言模型 CLIP 中提取的特征,该研究提出了一种通过开放性的自然语言指令对新物体进行操作,并展示了这种方法泛化到未见过的表达和新型物体的能力。
方法介绍
该研究分析了少样本和语言指导的操作,其中需要在没见过类似物体的情况下,给定抓取演示或文本描述,机器人就能拾取新物体。为了实现这一目标,该研究围绕预训练图像嵌入构建了系统,这也是从互联网规模的数据集中学习常识先验的可靠方法。
下图 1 描述了该研究设计的系统:机器人首先使用安装在自拍杆上的 RGB 相机拍摄一系列照片来扫描桌面场景,这些照片用于构建桌面的神经辐射场 (NeRF)。最重要的是,该神经辐射场经过训练不仅可以渲染 RGB 颜色,还可以渲染来自预训练视觉基础模型的图像特征。这会产生一种场景表征,称为蒸馏特征场(DFF),它将 2D 特征图的知识嵌入到 3D 体积中。然后,机器人参考演示和语言指令来抓取用户指定的物体。
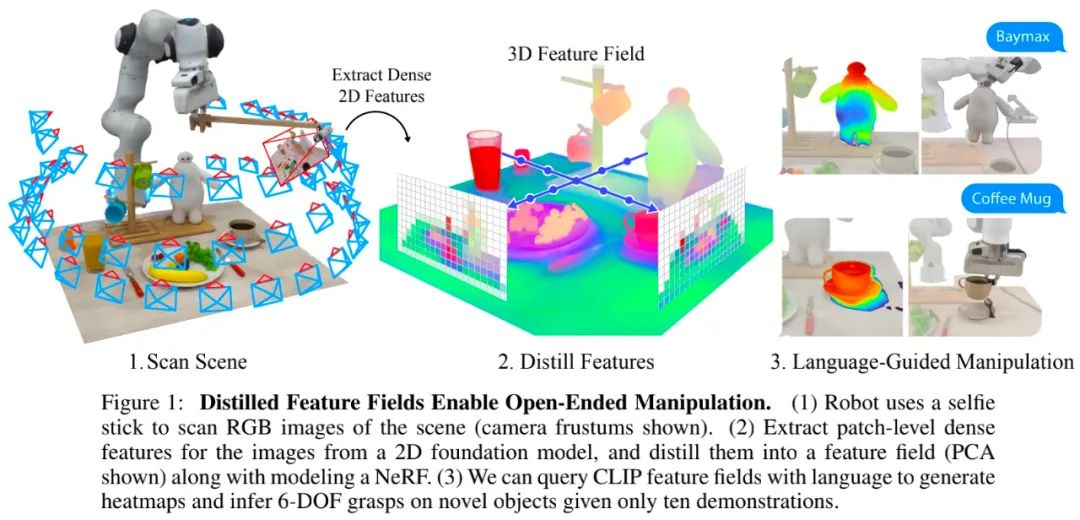
该研究的一大亮点是从 CLIP 模型中提取密集的二维特征,来给蒸馏特征场提供监督。此前,OpenAI 的 CLIP 模型仅提供图片尺度的全局特征,而 3D 神经场的生成需要密集的 2D 描述符。
为了解决这个问题,研究团队使用 MaskCLIP 对 CLIP 的视觉模型进行重新参数化,提取 patch 级密集特征。此方法不需要重新训练,可以保证其描述符与语言模型的对齐。
具身智能 (embodied intelligence) 囊括机器人,自动驾驶汽车等和物理世界有相互作用的人工智能体。这类智能体需要对物理世界同时进行几何空间和语义的理解来进行决策。
为了实现这样的表征能力,研究团队将视觉基础模型和视觉 - 语言基础模型中经过预训练的二维视觉表征通过可微分的三维渲染,构建为 3D 特征场。团队将这个方法运用在 6-DOF 机器人抓取任务上,这种方法叫作机器人操作特征场(Feature Fields for Robotic Manipulation,F3RM)的方法需要解决三个独立的问题:
首先,如何以合理的速度自动生成场景的特征场;
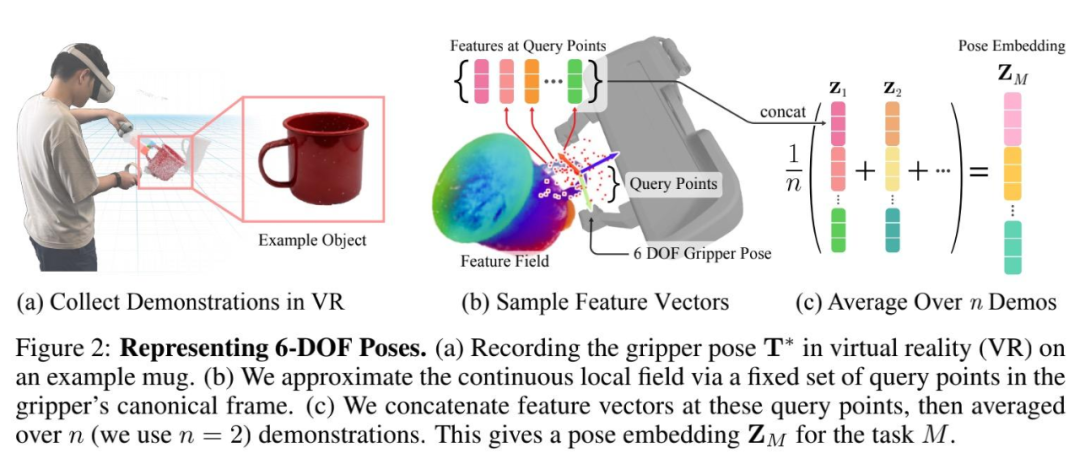
其次,如何表征和推断 6-DOF 抓取和放置的姿势;
最后,如何结合语言指导来实现开放文本命令。
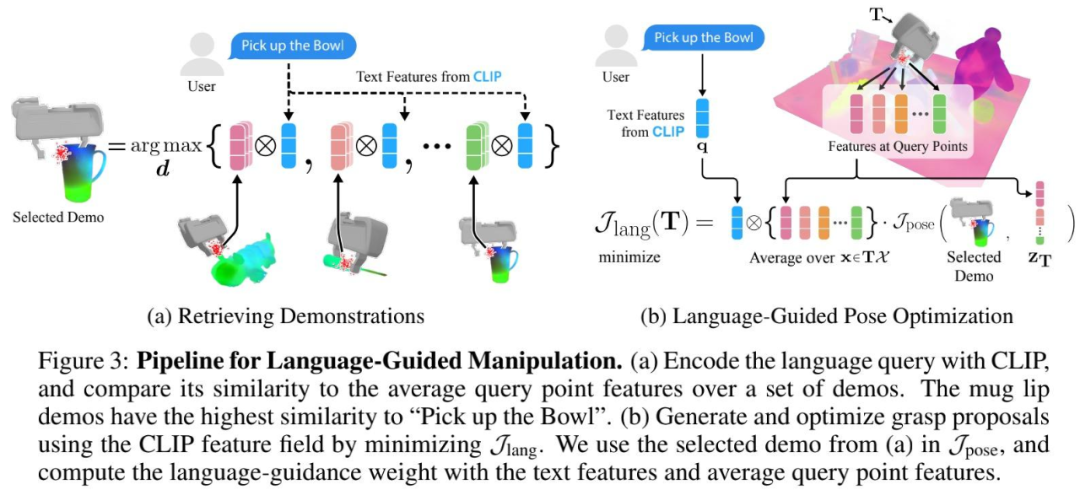
自然语言提供了一种将机器人操作扩展到开放物体集的方法,为目标物体照片不准确或不可用的情况提供了一种替代方案。在测试时,机器人接收来自用户的开放文本语言查询,其中指定要操作的物体。如下图 3 所示,语言指导的姿势推断过程包括三个步骤:
检索相关演示;
初始化粗略抓取;
语言指导的抓取姿势优化。
实验结果
我们先来看一些机器人抓取的实验效果。例如,使用 F3RM 方法,机器人可以轻松抓取一个螺丝刀工具:

抓取小熊玩偶:

抓取透明杯子和蓝色杯子:


把物体挂放在不同材质的架子上:


F3RM 还可以识别并抓取一些不常见的物体,比如化学领域会用到的量勺、量杯:


为了表明机器人能够利用 2D 基础模型中丰富的视觉和语言先验,并且可以泛化到未见过的新型物体上,该研究还进行了一系列抓取和放置任务的实验,我们来看下实验结果。
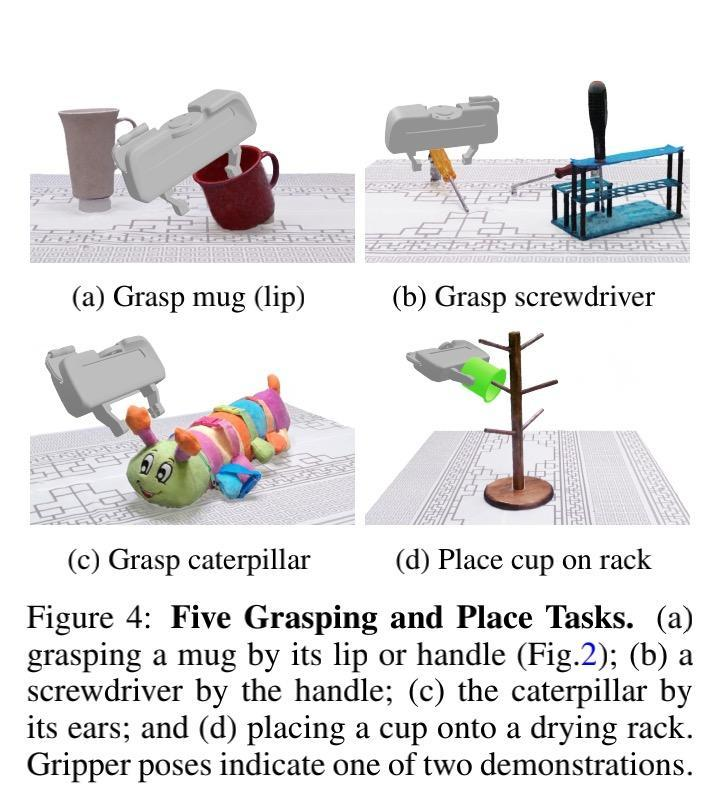
从示例中学会抓握
如下图 4 所示,该研究进行了 6-DOF 抓取和放置任务,并为每个任务提供两个演示。为了标记演示,该研究将 NeRF 重建的点云加载到虚拟现实中,并使用手动控制器将夹子移动到所需的姿势(图 2 (a))。
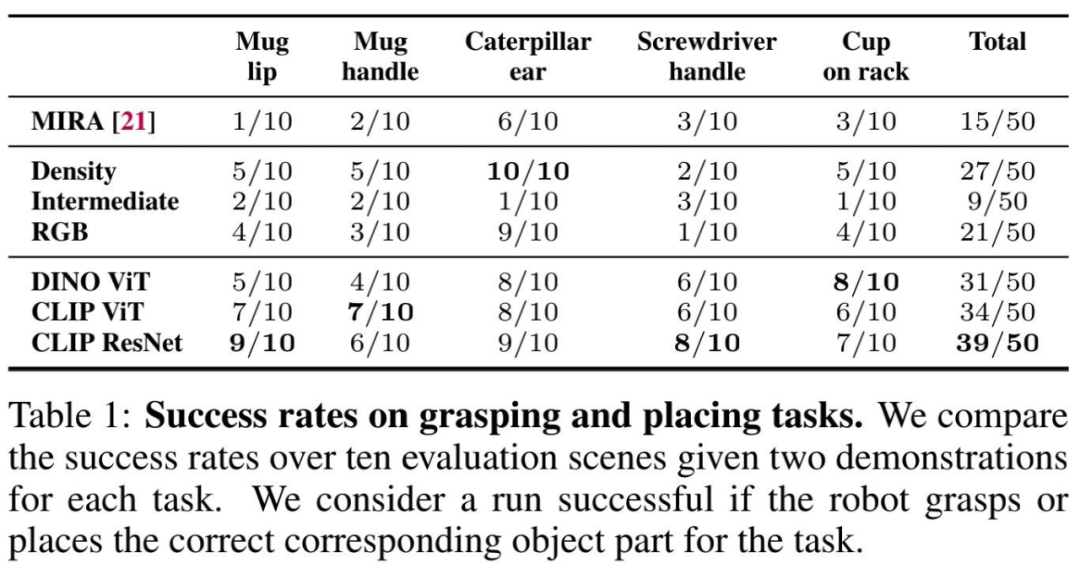
机器人在抓取和放置任务上的成功率如下表 1 所示:
下图 5 展示了该研究所提方法在未见过的新物体上的泛化情况:

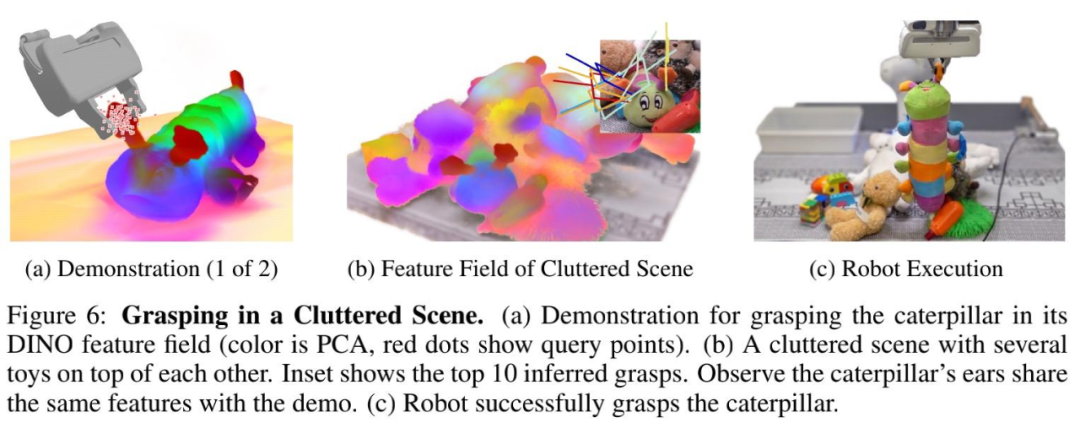
此外,语义特征和详细 3D 几何图形之间的融合提供了一种对密集的堆叠进行建模的方法。例如,在下图 6 (b) 中,毛毛虫玩具被埋在其他玩具下面。图 6 (c) 显示机器人抓住了毛毛虫玩具,并将其从玩具堆的底部拾起。
语言指导的机器人抓取
该研究设置了 13 个桌面场景来研究使用开放文本语言和 CLIP 特征场来指定要操作物体的可行性。
在下图 7 中,机器人在语言指导下成功执行了 5 个抓握。整个场景包含 11 个物体,其中 4 个来自 YCB 物体数据集。

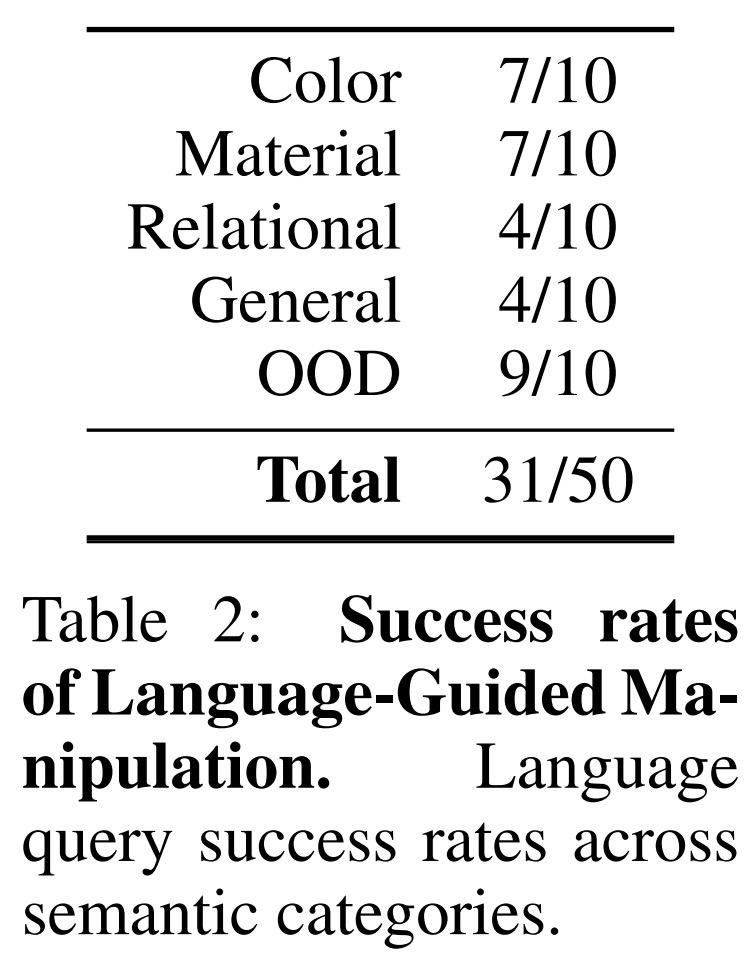
语言指导的操作成功率如下表 2 所示:
*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。


