单看数据结果是不够的,要仔细判断这些数据的可靠性。
预测风口、潮流是每个行业都热衷的事情。这可以让从业人员第一时间掌握行业的最新动向,成为行业某一时段的领军者。
音乐行业也同样如此。音乐公司都希望自己能够预测到下一次的音乐潮流,准确地挑选出下一首热门歌曲,赚个盆满钵满。那实现这种预测是可能的吗?
据《 Scientific American》与 《Axios》报道,这样的模型真的出现了,介绍它的论文甚至被称为可以改变音乐产业的文章。97% 的超高预测成功概率,能够让音乐公司不必再层层筛选,耗时耗力,而是通过模型就能够高效地预测出下个音乐「时尚单品」。这样的好办法何乐而不为呢?

事实真的如此吗?
在这篇论文发出前,已经有一些研究表示,音乐欣赏作为主观性极强的事情,任何结果都是有可能的:最好的歌曲很少表现不佳,最差的歌曲很少表现良好,但不代表这些情况全然不会出现。
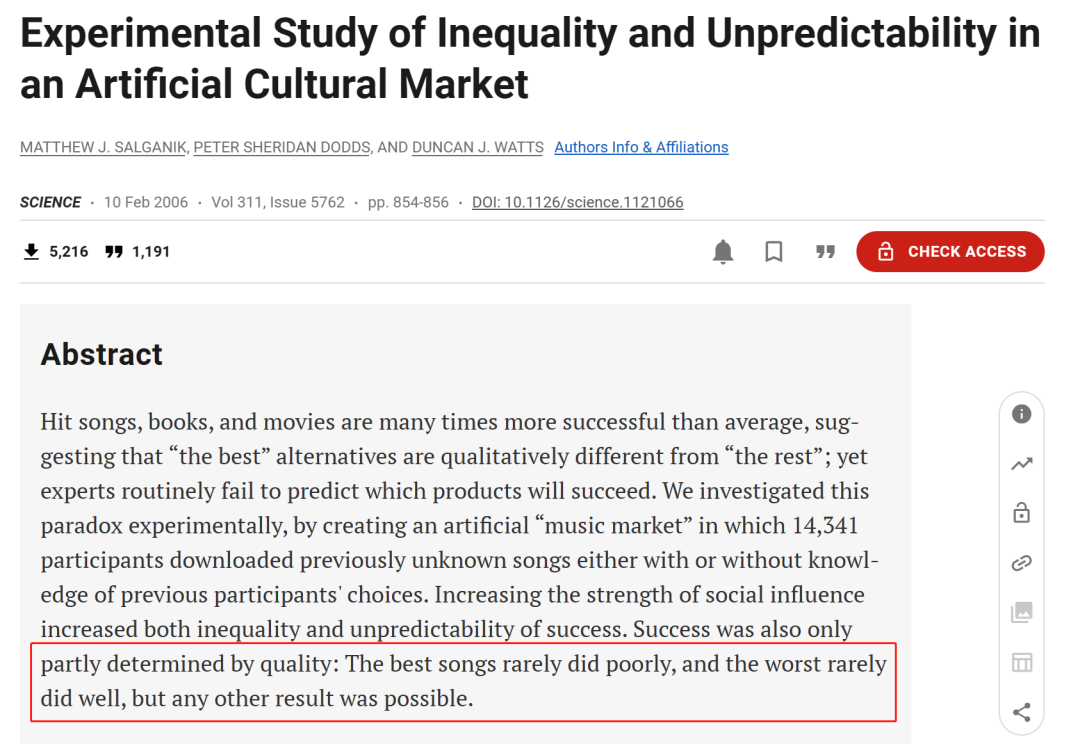
甚至有文章直接表示「本文认为,音乐预测还不是一项数据科学活动」。
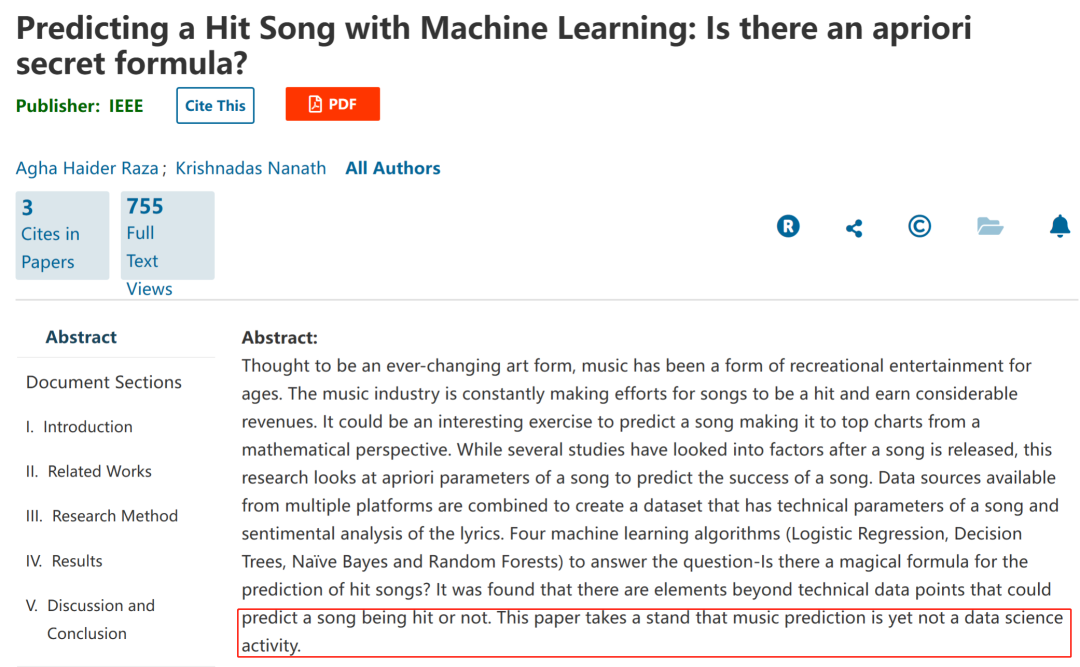
那么 97% 的预测成功概率如何实现的?是我们高估了预测难度还是低估了模型的能力?
有人指出,实际上并非如此。其实,人们现在还是无法用机器学习的方法来预测热门音乐。

文章地址:https://reproducible.cs.princeton.edu/predicting-hits.html
文中指出了这个预测热门音乐高准确率论文的纰漏:
论文作者使用了 33 位听众对 24 首歌曲的反应数据。他们的初始数据集由 24 个样本组成,每首歌曲一个样本。对于每首歌,模型只依赖三个特征来预测它是否会成为热门歌曲,这些特征的值取所有听众的平均值。他们利用这个数据集,通过一种叫做 「过度采样 」的方法,创建了一个包含 10000 个样本的合成(假)数据集。测试机器学习模型的主要考虑因素之一是,其训练数据应与评估数据应该完全分开。而本文的关键错误就在于,这种训练 - 测试分离是在数据已经过采样之后进行的。因此,训练数据和测试数据之间的相似度远远高于包含其他歌曲的新数据集。换句话说,论文没有提供模型在新歌曲上表现如何的证据。
当我们在作者发布的原始数据上修正这个误差后测试模型时,模型的准确性比随机好不了多少。我们还发现,使用作者的合成数据集,准确率实际上可以达到 100%。这并不奇怪:由于超采样程度如此之高,使用训练或测试分集都有可能重建原始数据。换句话说,他们是在基本相同的数据上进行训练和测试。
可见,97% 这个数据虽然看着不错,但可信度非常低,它并不能代表一个模型的能力,也并不证明音乐可以真正被预测。
这篇论文中介绍的模型存在机器学习中最常见的缺陷之一:数据泄漏。这意味着,模型是在与训练数据相同或相似的数据上进行评估的,这就夸大了对准确性的估计。在实际应用中,效果就会大打折扣。这相当于开卷考试 97 分的同学突然要闭卷考试,那么 97 分就不能作为衡量这位同学的成绩了。
其实数据泄漏这样的错误不仅仅出现在这一篇文章里。很多文章,甚至很多领域都出现了这种错误。
例如就在上个月, 2020 年的一篇著名肿瘤学论文中发现渗漏。而这篇文章发表在最负盛名的科学期刊之一《自然》上,而在发现错误之前已经积累了上百次的引用。

论文地址:https://www.biorxiv.org/content/10.1101/2023.07.28.550993v1.full.pdf
该研究报告了微生物与 33 种不同癌症类型之间的强相关性,并创建了机器学习预测器,其区分癌症的准确性接近完美。我们发现报告的数据和方法至少存在两个根本性的缺陷:
(1)基因组数据库和相关计算方法的错误导致所有样本中出现了数百万个细菌读数的假阳性结果,这主要是因为大多数被鉴定为细菌的序列实际上是人类的
(2)原始数据转换中的错误产生了一种人工特征,即使是对没有检测到读数的微生物也是如此,它为每种肿瘤类型标记了一个独特的信号,机器学习程序随后利用这个信号创建了一个表面上准确的分类器。
这些问题都使结果无效,从而得出结论:研究中提出的基于微生物组的癌症识别分类器是完全错误的。这些问题随后又影响了其他十几项已发表的研究。这些研究使用了相同的数据,其结果很可能也是无效的。
机器学习中常出现的问题
泄漏是基于 ml 的科学中的许多错误之一。这样的错误很常见的一个原因是,机器学习在各个科学领域中被随意采用,论文中报告机器学习结果的标准没有跟上步伐。过去在其他领域的研究发现,报告标准有助于提高研究的质量,但在少数领域以外的基于机器学习的科学中,这种标准并不存在。
除了泄漏外,解释错误同样也是一个常见的错误,这与论文中如何描述研究结果以及他人如何理解研究结果有很大关系。
一篇系统性综述发现,提出临床预测模型的论文通常会对其研究结果进行编造 — 例如,声称某个模型适合临床使用,但却没有证据表明该模型在其测试的特定条件之外也有效。这些错误并不一定夸大了模型的准确性。相反,它们夸大了模型可以在何时何地有效使用。

综述地址 https://www.sciencedirect.com/science/article/pii/S0895435623000756
另一个经常出现的疏忽是没有明确模型输出的不确定性水平。错误判断会导致对模型的错误信任。许多研究没有精确定义被建模的现象,导致研究结果的含义不明确。

相关论文地址:https://arxiv.org/abs/2206.12179
清单 REFORMS
既然这些错误这么常见,有没有什么办法可以避免呢?
有团队做出了清单 REFORMS((Reporting standards for Machine Learning Based Science) ,供大家参考,并能够最大限度地减少基于机器学习的科学研究中的错误,以及在错误悄然出现时使其更加明显。现在公开的是预印本。

文章地址:https://reforms.cs.princeton.edu/
这是一份包含 8 个模块、32 个项目的核对表,对开展机器学习科学研究的研究人员、审阅科学研究的裁判员以及提交和发表科学研究的期刊都有帮助。该清单由计算机科学、数据科学、社会科学、数学和生物医学研究领域的 19 位研究人员共同制定。作者的学科多样性对于确保这些标准在多个领域都有用至关重要。
这 8 个板块及 32 个项目如下所示,如果你也正在进行着相关研究,可以作为参考。





当然要解决基于计算机科学研究的所有缺陷,仅靠一份检查清单是远远不够的。但是考虑到错误的普遍性和缺乏系统的解决方案,该团队这样的一份清单是被迫切需要的。
参与清单制作的成员指出,如果基于计算机科学的研究都使用这份清单自查,那他们就不会费力给猪涂口红了(比喻想要把丑陋的事物变美好而做的无用功)。
*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。


